Date: Mon Nov 29 2004 - 17:59:33 LKT
To: Anuradha Ratnaweera <email-not-shown>
CC: Delan Silva <email-not-shown>, harshula <email-not-shown>
sequence 0daf + 0dd4 represents "du"To render correctly the correct "DU" is kept somewhere & cpu picks it up for rendering
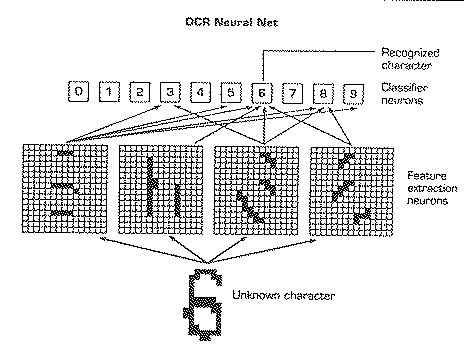
For OCR which works the other way need an absolute location. (example attached)
To give absolute locations for all characters need a matrix.
the same problem is with RI.
0DBB + ODD2 but RI is little different to "si"
The ispilla is at an angle on "ri" but on top of "sa" to make "si"
In SLS1134 do not have the joint characters and repaya so on. (story looping back)
Technically it is not neccessary to have four "A" in SLS 1134 if you talk of sequence.
Unconditonally we got to Correct & Improve the SLS 1134 to move forward.
I sent the Tamil jpg image for you to understand once the SLS 1134 is corrected I got to develop the Tamil.
All the Indic languages do have the same problem and only Hindi is moving out
Bangaldesh is redoing the system.
Once your IITC is over why not meet up. (except on Wed)
Best
Donald
Anuradha Ratnaweera wrote:
On Mon, 29 Nov 2004 11:08:15 +0600, Donald Gaminitillake <semage@mail.ewisl.net> wrote:You are getting closer to the problem :-)Good to hear... :-)When you key in the two locations (0DAF 0DD4) for the "DU" from where you got the correct "DU" the correct "DU" is located in a hidden placeLet's [for the moment] consider rendering to be a seperate "concern" from representation. So, let's [again for this moment] agree that representation of "dumriya" is not a problem if we agree [of course a big IF] that the sequence 0daf + 0dd4 represents "du". Then we will be able to store Sinhala characters without a problem. As for rendering, there are many ways to find out where "du" is: e.g. OpenType font format. Effectively, you can have shapes for sequences of character points (not only for single code points), using a table called GSUB. For example, it says 0daf is "da", 0daf+0dd4 is "du" and so on. OpenType format and tables is an open standard and in my knowledge, well supported by many platforms. In other words, Unicode / SLS 1134 contains *all* the characters either as single code points, or as sequences, and for the implementation, they can be represented in fonts.Then your IITC conferance will be more productive and effective for the development of Sri LankaAs for the conference and the ASOCIO exhibition, we are just participants... :-) About the Tamil software link you have sent, I don't believe that seperate software need to be developed. All the present internationalized software can be translated to Sinhala without touching a line of code. Anuradha